
蜘蛛程序,也被称为网络爬虫或网络蜘蛛,是一种自动化程序,用于在互联网上收集和整理信息。它们通常被搜索引擎使用,以便索引网页内容,使其能够被用户搜索到。蜘蛛程序会从互联网上的一个网页开始,然后遵循网页上的链接,跳转到其他网页,并重复这一过程,直到收集到足够的信息或覆盖到足够多的网页。
蜘蛛程序的工作流程大致如下:
1. 起始点:蜘蛛程序从一个或多个起始网页开始,这些网页可以是搜索引擎已知的重要网页,也可以是用户提交的网页。
2. 遍历蜘蛛程序会读取起始网页的内容,并提取出网页上的所有链接。它会根据一定的策略(如优先级、时间戳等)决定下一步要访问哪些链接。
3. 访问网页:蜘蛛程序会访问选定的链接,下载网页内容,并保存到本地或数据库中。
4. 分析内容:蜘蛛程序会对下载的网页内容进行分析,提取出有用的信息,如标题、正文、关键词等。这些信息将被用于构建搜索引擎的索引。
5. 更新索引:蜘蛛程序将提取的信息添加到搜索引擎的索引中,以便用户可以搜索到这些网页。
6. 重复过程:蜘蛛程序会重复上述过程,不断遍历新的链接,访问新的网页,并更新索引。
蜘蛛程序在互联网信息的收集和整理中起着至关重要的作用,它们使得搜索引擎能够为用户提供丰富、准确、及时的搜索结果。亲爱的读者们,你是否曾在深夜里,对着电脑屏幕,想象自己变成了一只在网络世界里自由穿梭的蜘蛛?今天,就让我带你一起揭开蜘蛛程序的神秘面纱,看看这个神奇的互联网小精灵是如何工作的。
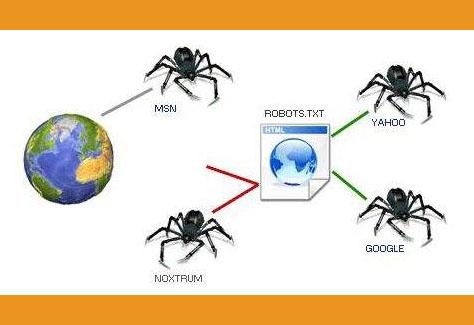
一、蜘蛛程序:网络世界的探险家
想象互联网就像一片浩瀚的星空,而蜘蛛程序就是那些勇敢的探险家。它们从一颗星星(也就是一个网页)出发,沿着链接的轨迹,不断探索着未知的领域。
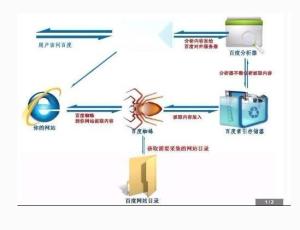
蜘蛛程序,又称网络爬虫或网页抓取器,是一种自动化程序,能够模拟人类在互联网上浏览和抓取数据的行为。它们通过发送HTTP请求,获取网页的HTML代码,然后解析这些代码以提取有用的数据。

二、蜘蛛程序的工作原理
蜘蛛程序的工作原理其实很简单,就像我们平时在网上冲浪一样。下面,就让我带你一步步了解这个神奇的过程。
1. 发现新网页:蜘蛛程序从一个或多个起始URL开始,通过分析网页内容中的链接,发现新的网页地址。
2. 发送HTTP请求:蜘蛛程序向这些新发现的网页地址发送HTTP请求,获取网页内容。
3. 解析网页内容:获取到网页内容后,蜘蛛程序会使用HTML解析器,如BeautifulSoup、lxml等,提取出有用的数据。
4. 存储数据:提取出的数据会被存储在数据库、CSV文件或Excel文件中,供后续分析使用。
5. 重复过程:蜘蛛程序会不断重复这个过程,探索更多的网页,收集更多的数据。
三、蜘蛛程序的应用
蜘蛛程序在互联网世界中扮演着重要的角色,它们的应用非常广泛。
1. 搜索引擎:蜘蛛程序是搜索引擎的核心组成部分,它们负责从互联网上抓取网页内容,建立索引,为用户提供搜索服务。
2. 数据挖掘:蜘蛛程序可以用于数据挖掘,从互联网上收集大量数据,用于市场分析、竞品分析等。
3. 网络监控:企业可以利用蜘蛛程序监控竞争对手的网站,了解其动态。
4. 内容分发:蜘蛛程序还可以用于内容分发,将网站内容推送到用户手中。
四、蜘蛛程序的挑战
虽然蜘蛛程序在互联网世界中发挥着重要作用,但它们也面临着一些挑战。
1. 网络速度:蜘蛛程序需要快速地发送HTTP请求,获取网页内容。如果网络速度慢,会影响其工作效率。
2. 数据量:互联网上的数据量巨大,蜘蛛程序需要处理大量的数据,这对它们的处理能力提出了挑战。
3. 网站反爬虫:一些网站为了防止被爬取,会设置反爬虫机制,这对蜘蛛程序来说是一个挑战。
五、
蜘蛛程序是互联网世界中的小精灵,它们在默默无闻地工作,为我们提供了丰富的网络资源。了解蜘蛛程序的工作原理,不仅能让我们更好地利用互联网,还能让我们对网络世界有更深入的认识。让我们一起感谢这些默默付出的蜘蛛程序,它们让我们的网络生活更加丰富多彩!
